![]()
Data Quality Constraints Library
Primer
Draft 2010-11-24
This version: http://semwebquality.org/documentation/primer/20101124/
Previous version: http://semwebquality.org/documentation/primer/20101124/
Latest version: http://semwebquality.org/documentation/primer/
Author: Christian Fürber, christian@fuerber.com (c) 2010 by Christian Fürber, http://www.fuerber.com.
This documentation is available under a Creative Commons Attribution-No Derivative Works 3.0 Germany License. You are free to use and distribute this document as long as it remains unchanged. Note that this license applies only to the documentation. The Data Quality Constraints Library itself is available under a GNU Lesser General Public License.
ABSTRACT
The Semantic Web allows the publication of data by anyone for everybody. A tremendous amount of data is already available on the web which may be used to retrieve information or integrate data into applications to enhance automation. If we do not care about the quality state of the published data, we will soon have a lot of poor data on the Semantic Web leading to disappointing experiences.
The Data Quality Constraints Library provides generic SPARQL query templates that may be used to identify different types of data quality problems. The query templates are designed based on the SPARQL Inferencing framework (SPIN) [1]. The query templates can easily be adjusted to any Semantic Web data set and are immediately available to detect data quality problems in the data. The constraints library may also be used for relational data in conjunction with wrapping technologies such as D2RQ.
The Data Quality Constraints Library is of interest for data publishers and data consumers. Data publishers may use the constraints to assure the published data is of high quality. Data consumers may use the constraints to check the quality state of the data before relying on it. The broad application of data quality constraints may, moreover, help to achieve trust in Semantic Web data.
STATUS OF THIS DOCUMENT
This documentation is a draft, reflecting the current version v1 of the Data Quality Constraints Library available at http://semwebquality.org/ontologies/dq-constraints#. It complements the SPIN framework.
DISCLAIMER
The constraints library and documentation are provided as they are, without warranty of any kind, expressed or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the constraint library or its documentation or the use or other dealings in the constraint library or documentation.
RELATED DOCUMENTS
- The Data Quality Constraint Library V1.0 is available at http://semwebquality.org/ontologies/dq-constraints#.
- For background information, see the papers Using SPARQL and SPIN for Data Quality Management on the Semantic Web and Using Semantic Web Resources for Data Quality Management
TABLE OF CONTENTS
- 1. INTRODUCTION
- 2. STEP-BY-STEP INSTRUCTIONS
- 2.1 Import Data Quality Constraints Library into TopBraid Composer
- 2.2 Step 1: Identify Data Quality Rules of the Domain
- 2.3 Step 2: Implement Quality Rules via the Data Quality Constraints Library
- 2.4 Step 3: Apply the Quality Constraints on your Data Set
- 2.5 Step 4: Analyze and Resolve Data Quality Problems
- 4. Aknowledgements
1. INTRODUCTION
In this section, we explain the need for data quality management, describe the data quality management (DQM) cycle, and explain how the data quality constraints can support DQM.
1.1 Need for Data Quality Management (DQM)
The amount of data published on the Semantic Web is continuously growing. We can use Semantic Web data to retrieve information from different domains or to integrate data into our applications for a higher degree in automation. Imagine you are searching for the best price for a certain type of cell phone in your area based on GoodRelations data, but the retrieved price information was outdated. Or you are a company that wants to publish the product catalogue on the Semantic Web and the data contains multiple errors. The flaws will be visible to everyone on web-scale.
The importance to manage the quality of your data will rise with increasing use of the Semantic Web. With our Data Quality Constraints Library you can now easily manage the quality of your Semantic Web data without the need for programming knowledge. The Data Quality Constraints Library has been designed for the Semantic Web technology stack and is based upon the SPARQL Inferencing Framework developed by Holger Knublauch (SPIN, http://spinrdf.org) [1].
1.2 Application Areas for the Constraints Library in the DQM Cycle
The data quality constraints library may be used (1) for the identification of data quality problems and (2) for quality assurance during data entry. The library shall support the data quality management process as defined by Wang [2] which consists of the following phases:
- Definition phase: The application of data quality constraints needs to be based upon the definition of what is good data for the domain of interest. Thus, you must analyze data quality requirements, such as required data values or functional dependencies between data elements, as a prerequisite to identify quality problems.
- Measurement phase: Based on the definition of data quality requirements we can identify data quality problems and measure the quality of the data source on hand.
- Analysis phase: The analysis phase covers the examination of potential data quality problems identified during the measurement phase. The main goal is thereby the identification of the root causes and the development of suitable correction approaches to remove data quality problems together with their root causes.
- Improvement phase: The most optimal correction approach needs to be applied during the improvement phase. The solution approach may thereby not only be of technical nature. In some cases organizational and business processes may need to be modified to remove the root cause of data quality problems.
2 STEP BY STEP INSTRUCTIONS
In the following, we show you how to set up and use the data quality constraints library.
2.1 Import Constraints Library into TopBraid Composer
You may easily import the data quality constraints library into TopBraid Composer. Simply push the import button ![]() in the imports view and enter the URL of the data quality constraints library, namely http://semwebquality.org/ontologies/dq-constraints# .
in the imports view and enter the URL of the data quality constraints library, namely http://semwebquality.org/ontologies/dq-constraints# .
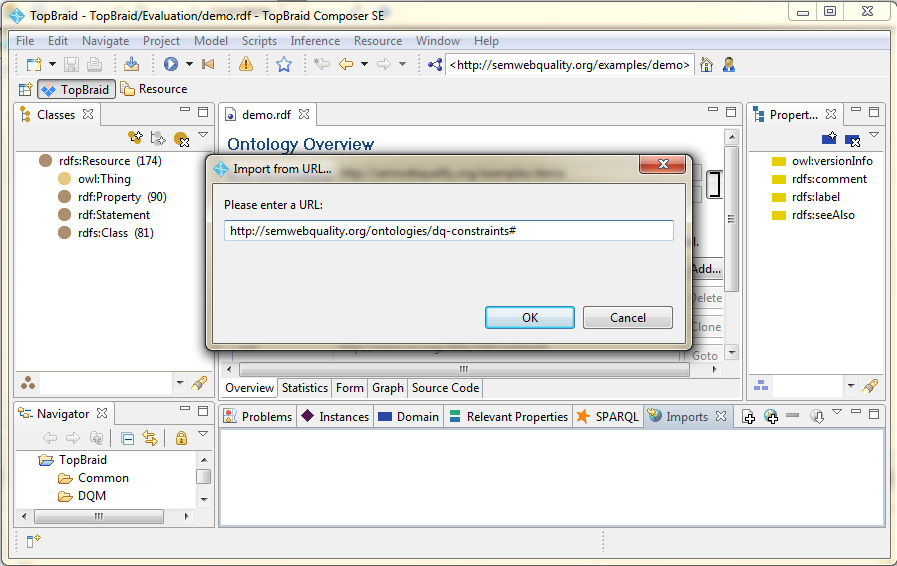
That's all! You have now access to the data quality constraints library! You can find the library within the spin ontology in the spin:Templates class.
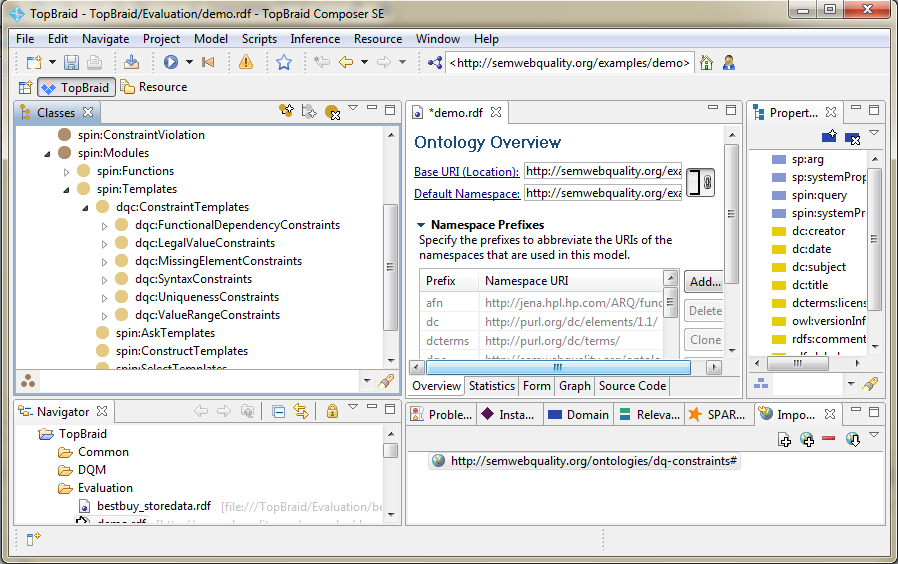
2.2 Step 1: Identify Data Quality Rules of the Domain
Before you can identify data quality problems in your data set, you need to define "what means high data quality for your domain?". The definition of data quality is at least influenced by
- standards: e.g ZIP-Codes,
- real world circumstances: e.g. the relationship between city and country,
- legal regulations: e.g. the availability of expiration dates for groceries,
- business policies: e.g. all TV's must have a value for screen size,
- IT needs: e.g. all dates must have the same syntax MM/DD/YYYY, or
- task requirements: e.g. population data for all populated places must be complete to calculate the world population.
Once, you have defined some rules you may proceed to step 2 to check the data for compliance of these rules.
PLEASE NOTE that due to incomplete knowledge you may need to return to this step later to redefine some rules, since you may discover that the rule is not concise enough or even incorrect.
2.3 Step 2: Implement Quality Rules via the Data Quality Constraints Library
As there are different types of data quality errors, we have created different types of data quality constraints for the identification of data quality problems. Hence, you need to choose the appropriate data quality constraints depending on your definition of data quality. E.g. if you defined that the property city must always have a literal value, then you could define a "dqc:MissingLiteralsAndProperties" constraint. You would thereby state that the property and value for city is mandatory in your data set. To access the constraints library within TopBraid Composer press ![]() next to spin:constraint and choose "Create from SPIN template...".
next to spin:constraint and choose "Create from SPIN template...".
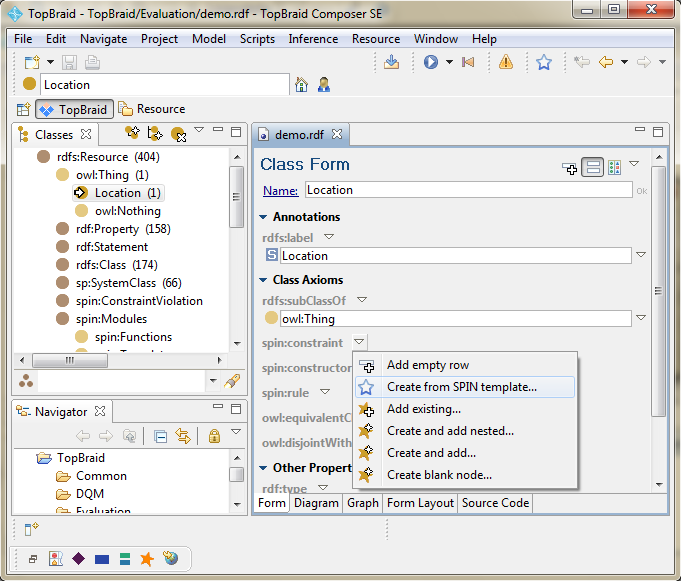
Then the screen below will pop up. In its upper left corner you can choose the appropriate data quality constraint template. In this example we want to define a syntax constraint on the property city that allows only strings with letters as literal values. Thus, we choose the "LettersAll" constraint, meaning that values for the property city must only contain letters. After you have chosen the property, it is important that you hit the enter button on your keyboard. Finally, you can click on OK.
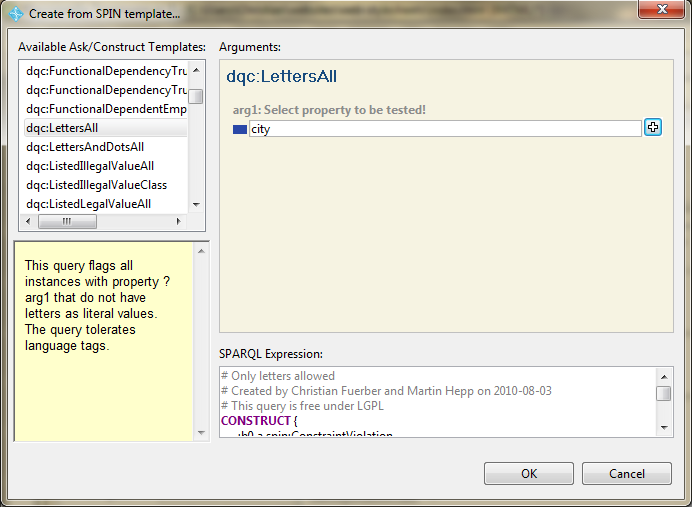
As you can see in the screenshot below, the syntax rule "only letters allowed in city!" has been defined and is listed in the property spin:constraint.
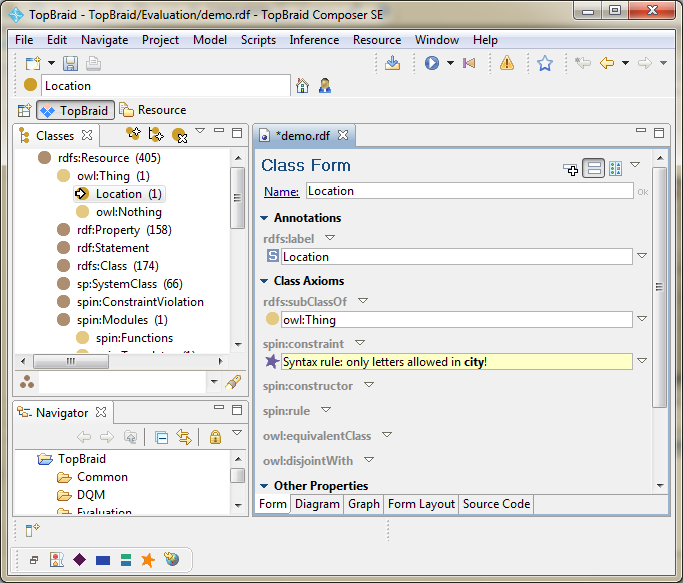
2.4 Step 3: Apply Quality Rules on the Data Set
We can now activate the rule by pushing ![]() . As you can see in the screenshot below, TopBraid Composer will flag all violated properties.
. As you can see in the screenshot below, TopBraid Composer will flag all violated properties.
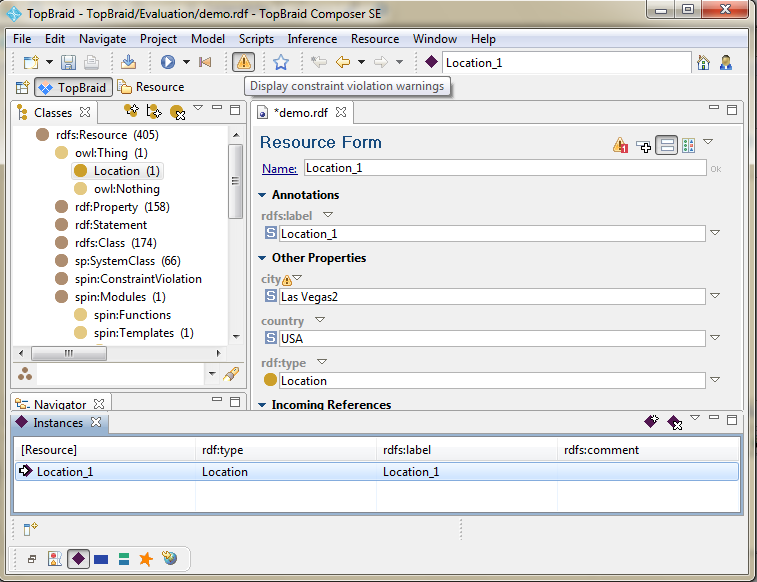
The attention sign is additionally shown on top of the middle screen of violated instances. If you push on it, you will see a pop up window indicating the problem that occured.
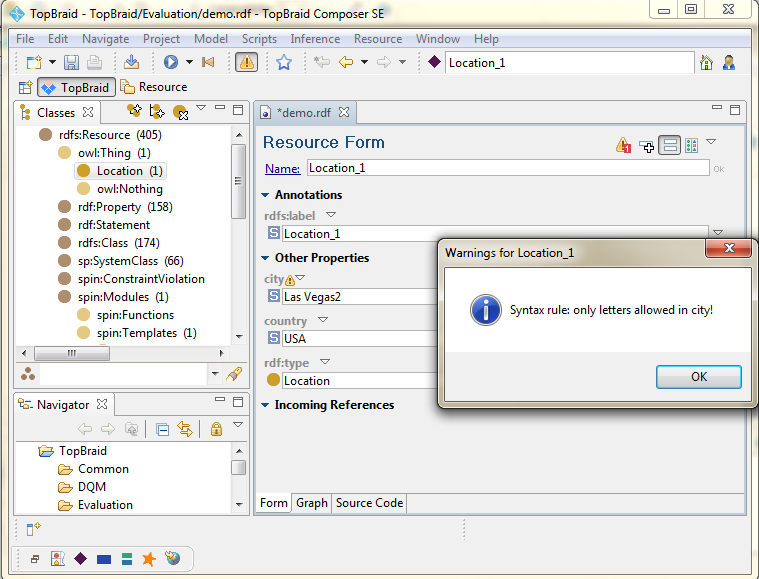
2.5 Step 4: Analyze and Resolve Data Quality Problems
Once you have discovered the data quality problems, you should indentify the source of the problem to avoid the return of the same problems over and over. This may require several activities, such as:
- the correction of data transfer processes and transformations
- the implementation of validations in data creation forms
- the modification of business processes, data policies, or naming conventions
- additional training for data creators
- the correction of data values
NOTE that due to incomplete knowledge your data quality rules may be incorrect or incomplete. Hence, you may need to return to Step 2 to delete an old rule and redefine it.
3 References
[1] Holger Knublauch, SPARQL Inferencing Notation (SPIN), http://spinrdf.org/
[2] Wang, R. Y. (1998). A product perspective on total data quality management. Commun. ACM, 41(2), 58-65.
[3] Fürber, Christian and Hepp, Martin: Using SPARQL and SPIN for Data Quality Management on the Semantic Web, in: BIS 2010. Proceedings of the 13th International Conference on Business Information Systems, May 3-5, 2010, Berlin, Germany, Springer LNBIP. See presentation
[4] Fürber, Christian and Hepp, Martin: Using Semantic Web Resources for Data Quality Management, in: Proceedings of the 17th International Conference on Knowledge Engineering and Knowledge Management (EKAW2010), October 11-15, 2010, Lisbon, Portugal, Springer LNCS Vol. 6317. See presentation
4 Acknowledgments
I would like to thank Martin Hepp, Holger Knublauch, Leyla Jael García Castro, and Andreas Radinger for the valuable inputs and their help regarding the creation and publication of the data quality constraints library.
Contact Information
E-Business and Web Science Research Group
Dipl.-Kfm. Christian Fürber
Universität der Bundeswehr München
Werner-Heisenberg-Weg 39
D-85579 Neubiberg, Germany
Phone: +49 89 6004-4218
eMail:christian(AT)fuerber.com
Twitter: http://twitter.com/cfuerber
Blog: http://www.fuerber.com/
Web: http://www.unibw.de/ebusiness/